Las colisiones de SHA-1 en el análisis forense
Recientemente hemos recibido la noticia de que el protocolo SHA-1 fue quebrado. En este artículo intentaré desentrañar cual es el impacto que este hecho tiene en las investigaciones digitales.
No importa cuán grande sea el objeto original, el HASH del mismo siempre tendrá el mismo tamaño, el cual depende del protocolo elegido.
Los protocolos de HASH usualmente utilizados en Informática Forense son el MD5 que produce una salida de 128 bits de longitud y el SHA-1 de 160 bits.
Por lo expuesto anteriormente, el HASH permitiría identificar cualquier contenido digital ya que al más mínimo cambio del origen, se produce una variación en el valor de HASH.
Resulta claro que si el resultado de aplicar una función de HASH produce un número fijo de bits, solo hay un conjunto finito de valores que puede tomar ese HASH.
En este punto es de hacer notar que las funciones de HASH también son utilizadas con fines criptográficos.
Es esto posible? Absolutamente ya que como he explicado el número de resultados posibles al aplicar el algoritmo, cualquiera sea este, es finito, mientras que los objetos a los que se les puede aplicar esa función son claramente infinitos.
De esta forma todos los protocolos de HASH tienen colisiones, solo que aquellos cuya longitud de salida es mayor, aún no han sido quebrados pues no se dispone de la potencia computacional para realizar los cálculos en un tiempo razonable, pero es cuestión de tiempo para hallar las colisiones de todos y cada uno de los protocolos de HASH existentes.
Cuando se demuestra que dos objetos diferentes producen el mismo valor de HASH , entonces ese protocolo debe discontinuarse para fines criptográficos pues el cifrado estaría comprometido.
El concepto de colisión de un HASH sería como encontrar dos personas que tuvieran las mismas huella digital…es esto posible? O por el contrario, se puede asegurar que no existen dos personas con las mismas huellas digitales? Ampliando este concepto a una investigación criminal y aun sin poder responder los interrogantes anteriores, la probabilidad de que una hipotética segunda persona tenga las mismas huellas digitales que otra y simultáneamente se encuentre vinculada al hecho investigado, es extremadamente baja e improbable.
Usar el argumento de la "duda razonable" es perfectamente posible aunque usualmente no da resultado positivo, en especial si se cuenta con alguna otra fuente de prueba.
Este doble factor podría encontrar una metáfora en el mundo real en la utilización simultánea de las huellas digitales y el ADN, por ejemplo, para identificar a una persona.
De esta forma, la probabilidad de que dos objetos diferentes tengan ambos valores de HASH coincidentes, sería soberanamente improbable.
Hasta el momento es una práctica común que los peritos utilicemos para este doble factor los protocolos de HASH MD5 y SHA-1, seguramente en un futuro próximo el SHA-1 será reemplazado por SHA-2, teniendo presente que del mismo hay en realidad cuatro implementaciones de longitudes diferentes SHA-224, SHA-256, SHA-384 y SHA-512 (el sufijo indica la longitud de bits) .

La utilización de SHA-2 definitivamente impactará en los tiempos de adquisición de evidencia, por la sobrecarga que implica el cálculo de funciones de mayor longitud.
En cualquier caso es solo cuestión de tiempo para que se encuentren colisiones en estos protocolos y la historia se vuelva a repetir.
Ing. Gustavo Presman - @gpresman
¿Qué es un HASH?
Es un algoritmo matemático que, aplicado sobre un objeto digital ya sea este el contenido de un disco rígido, un conjunto de archivos o simplemente un registro individual produce una salida hexadecimal de tamaño fijo.No importa cuán grande sea el objeto original, el HASH del mismo siempre tendrá el mismo tamaño, el cual depende del protocolo elegido.
Los protocolos de HASH usualmente utilizados en Informática Forense son el MD5 que produce una salida de 128 bits de longitud y el SHA-1 de 160 bits.
Por lo expuesto anteriormente, el HASH permitiría identificar cualquier contenido digital ya que al más mínimo cambio del origen, se produce una variación en el valor de HASH.
Resulta claro que si el resultado de aplicar una función de HASH produce un número fijo de bits, solo hay un conjunto finito de valores que puede tomar ese HASH.
En este punto es de hacer notar que las funciones de HASH también son utilizadas con fines criptográficos.
¿Qué es una colisión?
Una colisión se produce cuando al aplicar la función de HASH a dos objetos diferentes, ambos producen el mismo resultado.Es esto posible? Absolutamente ya que como he explicado el número de resultados posibles al aplicar el algoritmo, cualquiera sea este, es finito, mientras que los objetos a los que se les puede aplicar esa función son claramente infinitos.
De esta forma todos los protocolos de HASH tienen colisiones, solo que aquellos cuya longitud de salida es mayor, aún no han sido quebrados pues no se dispone de la potencia computacional para realizar los cálculos en un tiempo razonable, pero es cuestión de tiempo para hallar las colisiones de todos y cada uno de los protocolos de HASH existentes.
Cuando se demuestra que dos objetos diferentes producen el mismo valor de HASH , entonces ese protocolo debe discontinuarse para fines criptográficos pues el cifrado estaría comprometido.
¿Cuál es la utilidad de una función de HASH en una investigación digital?
Las funciones de hash se utilizan básicamente para dos cuestiones:- Asegurar la integridad de la evidencia digital: Esto se logra mediante el cálculo de la función de HASH al momento de su recolección, el cual debe verificarse en todas las etapas posteriores de peritaje de la misma.
- Identificación de contenido binario: Es el procedimiento mediante el cual se le aplica la función de HASH a un archivo o conjunto de archivos con el objeto de identificarlos en algún otro dispositivo de almacenamiento digital.
El concepto de colisión de un HASH sería como encontrar dos personas que tuvieran las mismas huella digital…es esto posible? O por el contrario, se puede asegurar que no existen dos personas con las mismas huellas digitales? Ampliando este concepto a una investigación criminal y aun sin poder responder los interrogantes anteriores, la probabilidad de que una hipotética segunda persona tenga las mismas huellas digitales que otra y simultáneamente se encuentre vinculada al hecho investigado, es extremadamente baja e improbable.
Usar el argumento de la "duda razonable" es perfectamente posible aunque usualmente no da resultado positivo, en especial si se cuenta con alguna otra fuente de prueba.
¿Qué hacemos entonces con la evidencia digital ante este escenario?
El problema no es nuevo, ya ocurrió cuando se encontraron las colisiones de MD5 y a pesar de que la probabilidad de tener dos objetos distintos, asociados a la misma investigación, con igual valor de HASH MD5 es muy baja, la comunidad forense reaccionó sugiriendo la utilización de dos funciones de HASH por cada objeto.Este doble factor podría encontrar una metáfora en el mundo real en la utilización simultánea de las huellas digitales y el ADN, por ejemplo, para identificar a una persona.
De esta forma, la probabilidad de que dos objetos diferentes tengan ambos valores de HASH coincidentes, sería soberanamente improbable.
Hasta el momento es una práctica común que los peritos utilicemos para este doble factor los protocolos de HASH MD5 y SHA-1, seguramente en un futuro próximo el SHA-1 será reemplazado por SHA-2, teniendo presente que del mismo hay en realidad cuatro implementaciones de longitudes diferentes SHA-224, SHA-256, SHA-384 y SHA-512 (el sufijo indica la longitud de bits) .
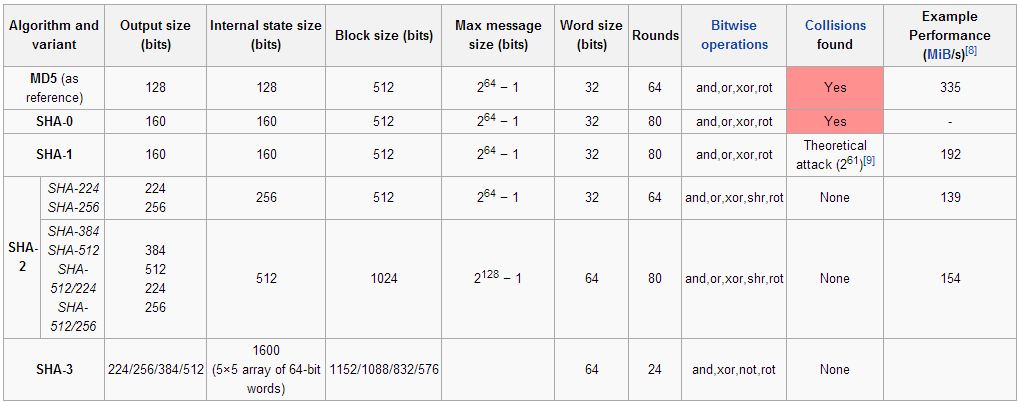
La utilización de SHA-2 definitivamente impactará en los tiempos de adquisición de evidencia, por la sobrecarga que implica el cálculo de funciones de mayor longitud.
En cualquier caso es solo cuestión de tiempo para que se encuentren colisiones en estos protocolos y la historia se vuelva a repetir.
Ing. Gustavo Presman - @gpresman
Via: blog.segu-info.com.ar
Las colisiones de SHA-1 en el análisis forense
 Reviewed by Zion3R
on
16:49
Rating:
Reviewed by Zion3R
on
16:49
Rating:
Reviewed by Zion3R
on
16:49
Rating:




{kind=link}