¿Utilizar Inteligencia Artificial Para Convertirnos En Mejores Músicos? Parte 1 De 3
El mundo de la Inteligencia Artificial tiene también un prometedor impacto en el dominio del arte, gracias a la aparición y el desarrollo del Deep Learning. Un claro ejemplo esclarecedor del potencial de la IA en este campo lo hemos visto con DALL-E 2, desarrollado por OpenAI, un sistema capaz de generar arte a partir de lo que le indique el usuario en una frase, destacando por su alta capacidad de adaptarse y representar con buena calidad prácticamente cualquier petición.

En la imagen siguiente se muestra lo que este sistema representa ante la entrada “An astronaut riding a horse in a photorealistic style”. Y como veis el resultado en más que prometedor en esta disciplina de la llamada Generative-AI. El uso de la IA en este campo ya es una realidad, y el futuro que podemos esperar de ello es absolutamente prometedor.

¿Y si pudiéramos entrenar a una Inteligencia Artificial para que representara imágenes nuevas o ya existentes con el estilo del mismísimo Van Gogh? ¿Y si pudiéramos crear un modelo que escribiese como el propio William Shakespeare? ¿Y a componer como Beethoven? ¿O transformar un texto al estilo de Arturo Pérez-Reverte en las novelas de El Capitán Alatriste como hicieron los compañeros con Maquet? Si has echado un vistazo a los artículos referenciados, habrás podido ver que estas preguntas no se tratan de utopías, sino que, independientemente de la calidad final, ya son ejemplos que se han podido realizar con Inteligencia Artificial.

Figura 2: Ejemplo de uso de DALL-E 2
¿Y si pudiéramos entrenar a una Inteligencia Artificial para que representara imágenes nuevas o ya existentes con el estilo del mismísimo Van Gogh? ¿Y si pudiéramos crear un modelo que escribiese como el propio William Shakespeare? ¿Y a componer como Beethoven? ¿O transformar un texto al estilo de Arturo Pérez-Reverte en las novelas de El Capitán Alatriste como hicieron los compañeros con Maquet? Si has echado un vistazo a los artículos referenciados, habrás podido ver que estas preguntas no se tratan de utopías, sino que, independientemente de la calidad final, ya son ejemplos que se han podido realizar con Inteligencia Artificial.
 |
| Figura 3: Libro de Machine Learning aplicado a Ciberseguridad de Carmen Torrano, Fran Ramírez, Paloma Recuero, José Torres y Santiago Hernández |
Por aquí hemos visto muchos artículos en los que utilizar Inteligencia Artificial y Machine Learning a Ciberseguridad, pero en este artículo, en particular, nos orientaremos en relación con la generación de música, y revisaremos diferentes formas que existen actualmente en el ámbito de la IA para realizar esto, pero siempre teniendo en cuenta que las arquitecturas que se comentarán no son solo exclusivas para la generación de música.
Generación de música con IA
La creación de música supone un gran desafío dentro del mundo de la Inteligencia Artificial, debido a su temporalidad (existen dependencias entre las notas a lo largo del tiempo), el múltiple uso de instrumentos sonando a la vez y, por último, los acompañamientos musicales, de manera que en cada espacio de tiempo se pueden tener diferentes salidas a generar.
Es importante mencionar que, a los algoritmos de IA destinados a la generación de música, en la mayoría de los casos se los alimenta procesando archivos MIDI (Music Instrument Digital Interface). Un fichero MIDI es una representación simbólica de la música, al igual que el texto para el habla. Básicamente, en él se almacena información como las notas musicales, tono y velocidad, volumen, tempo… De esta manera, esta información procesada se alimenta al algoritmo, cuyo resultado se puede cargar como archivo MIDI también. Sin embargo, existen excepciones de algoritmos que no utilizan este tipo de información, como es el caso de WaveNet, donde se utilizan las propias ondas de audio.
Actualmente, existen varias formas de generar música con IA, a continuación, vamos a hacer un repaso a las más representativas.
Redes Neuronales Recurrentes (RNN) – Un único instrumento
La aproximación más básica se trata del uso de las redes neuronales recurrentes (RNN), donde se realicen predicciones sobre la próxima nota a tocarse, similar a modelos de lenguaje en NLP. De esta manera, se genera un ciclo de realimentación donde constantemente propagando al modelo la nota última generada se crea otra. Las RNN tienen una estructura que las permite tener cierta “memoria” temporal, lo que es perfecto para la generación de contenido dependiente con el tiempo, es decir, teniendo en cuenta las notas pasadas. En la imagen siguiente se muestra un ejemplo de la arquitectura de una RNN.

Para esta aproximación, el modelo se entrena tomando como datos de entrada conjuntos de secuencias de notas y ofrece como salida la correspondiente siguiente nota de cada conjunto (la información se obtiene procesando el archivo MIDI). De esta manera, como salida de la red se generan una serie de probabilidades sobre la siguiente nota a tocarse, y se escogería en base a alguna distribución de probabilidad la siguiente nota (no se escoge la nota con mayor probabilidad de ser tocada para promover mayor variación).
La creación de música supone un gran desafío dentro del mundo de la Inteligencia Artificial, debido a su temporalidad (existen dependencias entre las notas a lo largo del tiempo), el múltiple uso de instrumentos sonando a la vez y, por último, los acompañamientos musicales, de manera que en cada espacio de tiempo se pueden tener diferentes salidas a generar.
Es importante mencionar que, a los algoritmos de IA destinados a la generación de música, en la mayoría de los casos se los alimenta procesando archivos MIDI (Music Instrument Digital Interface). Un fichero MIDI es una representación simbólica de la música, al igual que el texto para el habla. Básicamente, en él se almacena información como las notas musicales, tono y velocidad, volumen, tempo… De esta manera, esta información procesada se alimenta al algoritmo, cuyo resultado se puede cargar como archivo MIDI también. Sin embargo, existen excepciones de algoritmos que no utilizan este tipo de información, como es el caso de WaveNet, donde se utilizan las propias ondas de audio.
Actualmente, existen varias formas de generar música con IA, a continuación, vamos a hacer un repaso a las más representativas.
Redes Neuronales Recurrentes (RNN) – Un único instrumento
La aproximación más básica se trata del uso de las redes neuronales recurrentes (RNN), donde se realicen predicciones sobre la próxima nota a tocarse, similar a modelos de lenguaje en NLP. De esta manera, se genera un ciclo de realimentación donde constantemente propagando al modelo la nota última generada se crea otra. Las RNN tienen una estructura que las permite tener cierta “memoria” temporal, lo que es perfecto para la generación de contenido dependiente con el tiempo, es decir, teniendo en cuenta las notas pasadas. En la imagen siguiente se muestra un ejemplo de la arquitectura de una RNN.

Figura 4: Arquitectura RNN
Para esta aproximación, el modelo se entrena tomando como datos de entrada conjuntos de secuencias de notas y ofrece como salida la correspondiente siguiente nota de cada conjunto (la información se obtiene procesando el archivo MIDI). De esta manera, como salida de la red se generan una serie de probabilidades sobre la siguiente nota a tocarse, y se escogería en base a alguna distribución de probabilidad la siguiente nota (no se escoge la nota con mayor probabilidad de ser tocada para promover mayor variación).
Esta aproximación es la más simple y por ello la que ofrece resultados más pobres, además, esta solución no es escalable a la generación de notas con múltiples instrumentos, puesto que las combinaciones de posibles notas a predecir crecerían de manera exponencial, y además se restringe a que todas las notas tengan la misma longitud, lo cual no se asemeja a la realidad.
Redes Neuronales Recurrentes – Múltiples instrumentos
En este caso, en vez de trabajar para predecir una única nota de solo un instrumento, se tiene en cuenta en cada momento de tiempo el piano roll con todos los instrumentos que aparezcan (este se puede obtener procesando el archivo MIDI de la melodía).
El piano roll es una representación discreta de la música que es inteligible para muchos algoritmos de aprendizaje automático, pueden verse como un espacio de dos dimensiones, con el "tiempo" en el eje horizontal y el "tono" en el eje vertical. Un uno o un cero en cualquier posición de este espacio indica si una nota fue tocada o no en ese momento para ese tono. En la Figura 4 se muestra un ejemplo visual de un piano roll.

De esta manera, se entrena la RNN para predecir la próxima lista de notas (el tamaño de esta lista será el producto entre el número de instrumentos y los 128 tonos de notas a generar, estos son los tonos definidos en MIDI), y de esta forma mediante el ciclo de realimentación característico de las RNNs se va generando la melodía. Esta aproximación presenta dificultades a la hora de generar música que logre complementar los sonidos de todos los instrumentos involucrados, de manera que estos tengan “sentido” (aunque este aspecto se trata más de una percepción subjetiva).
Redes Neuronales Convolucionales (CNN)
En el dominio de las CNNs destaca WaveNet, un modelo generativo de audio raw desarrollado por Google DeepMind. Este modelo recibe como entrada un trozo de una onda de audio raw, es decir, la representación de sus amplitudes en diferentes intervalos de tiempo. Estas entradas se pre-procesan en una serie de valores numéricos que definen cada amplitud, y esta es la información que se introduce a la red. En la imagen siguiente se muestra una onda de audio.

De esta manera, dada la entrada comentada, el modelo intenta predecir el valor de amplitud siguiente, y esta predicción se “inserta” dentro del conjunto de datos de entrada para la siguiente iteración, eliminando el primer valor en el nuevo conjunto, de manera que es como una cadena donde se elimina el valor situado en primer lugar y se inserta en el último lugar la última predicción realizada.
Redes Neuronales Recurrentes – Múltiples instrumentos
En este caso, en vez de trabajar para predecir una única nota de solo un instrumento, se tiene en cuenta en cada momento de tiempo el piano roll con todos los instrumentos que aparezcan (este se puede obtener procesando el archivo MIDI de la melodía).
El piano roll es una representación discreta de la música que es inteligible para muchos algoritmos de aprendizaje automático, pueden verse como un espacio de dos dimensiones, con el "tiempo" en el eje horizontal y el "tono" en el eje vertical. Un uno o un cero en cualquier posición de este espacio indica si una nota fue tocada o no en ese momento para ese tono. En la Figura 4 se muestra un ejemplo visual de un piano roll.

Figura 5: Ejemplo visual de un piano roll
Redes Neuronales Convolucionales (CNN)
En el dominio de las CNNs destaca WaveNet, un modelo generativo de audio raw desarrollado por Google DeepMind. Este modelo recibe como entrada un trozo de una onda de audio raw, es decir, la representación de sus amplitudes en diferentes intervalos de tiempo. Estas entradas se pre-procesan en una serie de valores numéricos que definen cada amplitud, y esta es la información que se introduce a la red. En la imagen siguiente se muestra una onda de audio.

Figura 6: Onda de audio raw
De esta manera, dada la entrada comentada, el modelo intenta predecir el valor de amplitud siguiente, y esta predicción se “inserta” dentro del conjunto de datos de entrada para la siguiente iteración, eliminando el primer valor en el nuevo conjunto, de manera que es como una cadena donde se elimina el valor situado en primer lugar y se inserta en el último lugar la última predicción realizada.
Este modelo utiliza las llamadas Dilated Causal 1D Convolution layers. Es decir, en primer lugar, se emplean convoluciones de una dimensión, de manera que los filtros se van aplicando en una única dirección, esto permite reconocer patrones en secuencias. Además, se tratan de Causal Convolutions porque la convolución que se realiza para generar un valor en un tiempo t depende únicamente de los valores que se tienen desde ese punto t hacia atrás en el tiempo.
Sin embargo, estas tienen una limitación y es que su campo receptivo es pequeño, y no pueden tener en cuenta valores lejanos en el tiempo a la hora de generar la secuencia. De este modo, por ello se realizan las Dilated Causal Convolutions de una dimensión, la cual consiste en crear una serie de huecos entre los valores del kernel a aplicarse en la convolución (parámetro conocido como ratio de dilatación) que permite aumentar el campo receptivo. En la figura siguiente se muestra un ejemplo.
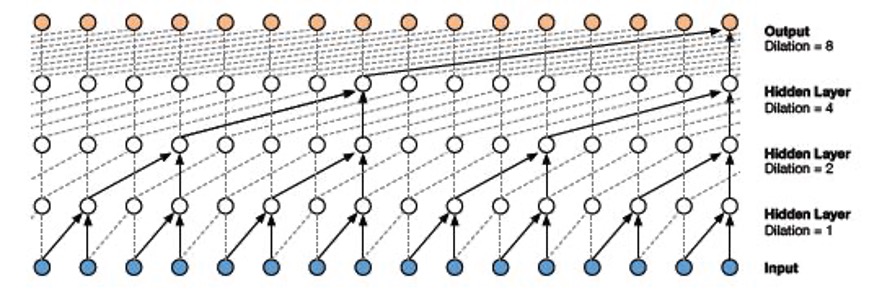
Figura 7: Ejemplo Dilated Causal Convolutions
Además, WaveNet utiliza también bloques residuales que tienen acción tras aplicarse la convolución comentada, para agilizar el proceso. Para más información, consultar el paper original.
Variational Autoencoders (VAE)
A grandes rasgos, un autoencoder es una red de neuronas artificial que se aprende la representación de los datos de entrada, es decir, sus características más críticas (concepto conocido como espacio latente), y posteriormente intenta recrear estas entradas. Por ello, dada su arquitectura, un autoencoder aprende a “reconstruir” las entradas originales. Sin embargo, en la práctica no suelen generar espacios latentes demasiado útiles, y estos han quedado de manera general desfasados por los Variational AutoEncoders (VAE).
Un variational autoencoder es un autoencoder pensado para generar nuevos datos mediante el uso de distribuciones de probabilidad, lo que garantiza la generación de datos con modificaciones respecto a la entrada. Por ejemplo, si se tiene una imagen de un gato como entrada, se irían generando diferentes gatos dependiendo de qué características se hayan escogido para la decodificación, de manera aleatoria, de la distribución. En la Figura 8 se muestra un ejemplo de esta arquitectura, para más información consultar el paper original.

Este esquema se puede utilizar para generar música. Por ejemplo, mediante la introducción de ondas de audio en un variational autoencoder se podrían crear nuevas, gracias a la arquitectura de este tipo de redes que permite la generación de contenido nuevo, como ya se ha comentado.
Figura 8: Ejemplo de arquitectura VAE
Este esquema se puede utilizar para generar música. Por ejemplo, mediante la introducción de ondas de audio en un variational autoencoder se podrían crear nuevas, gracias a la arquitectura de este tipo de redes que permite la generación de contenido nuevo, como ya se ha comentado.
(Continúa en la segunda parte de este artículo)
- ¿Utilizar Inteligencia Artificial para convertirnos en mejores músicos? Parte 1
- ¿Utilizar Inteligencia Artificial para convertirnos en mejores músicos? Parte 2
- ¿Utilizar Inteligencia Artificial para convertirnos en mejores músicos? Parte 3
**************************************************************************************************
Saludos,
Autor: Javier del Pino Díaz (Intership en Ideas Locas)

Via: www.elladodelmal.com
¿Utilizar Inteligencia Artificial Para Convertirnos En Mejores Músicos? Parte 1 De 3
 Reviewed by Zion3R
on
0:17
Rating:
Reviewed by Zion3R
on
0:17
Rating:
Reviewed by Zion3R
on
0:17
Rating:



