¿Utilizar Inteligencia Artificial Para Convertirnos En Mejores Músicos? Parte 2 De 3
En la primera parte de este artículo vimos cómo la creación de música supone un gran desafío dentro del mundo de la Inteligencia Artificial, y cómo funcionan diferentes aproximaciones, como el uso de Redes Neurolanes Recurrentes (RNN) para uno o para múltiples instrumentos, Redes Neuronales Convolucionales (CNN) o de Variational Autoencoders.

Figura 9: ¿Utilizar Inteligencia Artificial para convertirnos
en mejores músicos? Parte 2 de 3
En esta parte vamos a seguir analizando el uso de aproximaciones basadas en GAN o Transformers, para ver las posibilidades de Generative-AI para el mundo de la música.
GANs
En una red generativa antagónica (Generative Adversarial Networks, GAN) se tienen dos modelos, un Generador y un Discriminador. La idea es que exista una competición entre estas, y para entenderse con un ejemplo, se puede suponer que el generador está tratando de intentar falsificar un documento, mientras que el Discriminador trata de verificar si el documento es falso o no. La idea es que mientras el modelo Generador se va convirtiendo en un mejor falsificador, el Discriminador consecuentemente se va convirtiendo en un mejor detector, de manera que con cada iteración se va generando mejor y mejor contenido.

En el contexto del Deep Learning, el modelo Discriminador es entrenado mediante datos reales y falsos (etiquetados con “real” o “fake”), mientras que por cada salida de este modelo el generador es ajustado para que sea más probable que su salida sea aceptada como real por parte del Discriminador. El Generador actúa como una CNN al revés, es decir, recibe como entrada un vector de números aleatorios, y produce como salida por ejemplo una matriz de tres dimensiones. Y esta salida es alimentada al Discriminador, que opera como una CNN normal para decidir si el contenido es real o falso. En la figura siguiente se muestra la arquitectura de una GAN, para más información consultar el paper original.

En el caso de la generación de música, es posible introducir como entrada un vector de números aleatorios al generador con el objetivo de crear una salida de una matriz con unas dimensiones requeridas para recrear un tema musical, por ejemplo, las dimensiones correspondientes al producto entre diferentes secuencias de la melodía junto con el número de instrumentos y los 128 tonos definidos en MIDI (por ejemplo, si se divide la canción en secuencias de 64 partes y se tienen 4 instrumentos, se tendría una matriz de 64x128x4).
GANs
En una red generativa antagónica (Generative Adversarial Networks, GAN) se tienen dos modelos, un Generador y un Discriminador. La idea es que exista una competición entre estas, y para entenderse con un ejemplo, se puede suponer que el generador está tratando de intentar falsificar un documento, mientras que el Discriminador trata de verificar si el documento es falso o no. La idea es que mientras el modelo Generador se va convirtiendo en un mejor falsificador, el Discriminador consecuentemente se va convirtiendo en un mejor detector, de manera que con cada iteración se va generando mejor y mejor contenido.
Figura 10: Paper original de las GANs
En el contexto del Deep Learning, el modelo Discriminador es entrenado mediante datos reales y falsos (etiquetados con “real” o “fake”), mientras que por cada salida de este modelo el generador es ajustado para que sea más probable que su salida sea aceptada como real por parte del Discriminador. El Generador actúa como una CNN al revés, es decir, recibe como entrada un vector de números aleatorios, y produce como salida por ejemplo una matriz de tres dimensiones. Y esta salida es alimentada al Discriminador, que opera como una CNN normal para decidir si el contenido es real o falso. En la figura siguiente se muestra la arquitectura de una GAN, para más información consultar el paper original.
Figura 11: Arquitectura GAN
En el caso de la generación de música, es posible introducir como entrada un vector de números aleatorios al generador con el objetivo de crear una salida de una matriz con unas dimensiones requeridas para recrear un tema musical, por ejemplo, las dimensiones correspondientes al producto entre diferentes secuencias de la melodía junto con el número de instrumentos y los 128 tonos definidos en MIDI (por ejemplo, si se divide la canción en secuencias de 64 partes y se tienen 4 instrumentos, se tendría una matriz de 64x128x4).

De esta manera, mediante la competición comentada entre modelo Discriminador y Generador se puede llevar a cabo la generación de melodías. Entonces, sería posible entrenar a un modelo capaz de simular por ejemplo la música de Mozart, alimentando al modelo Discriminador con su música y las melodías generadas por el modelo generador e intentando que este último compusiera melodías similares. Un algoritmo famoso de generación de música que utiliza esta estructura es MidiNet.
Transformers
Los Transformers son un tipo de red neuronal muy famosas en el ámbito del procesamiento del lenguaje natural, que han dado lugar a la generación de enormes modelos generadores de lenguaje, entre otras cosas, como GPT-3, desarrollado por OpenAI. Dadas una serie de palabras de entrada son capaces de generar párrafos enteros con una gran coherencia, y este tipo de modelos se caracterizan por tener una gran memoria, algo que por ejemplo constituía una limitación en las redes neuronales recurrentes.

A grandes rasgos, este tipo de modelos trabajan con las denominadas capas de atención, las cuales codifican, por ejemplo, si se trata de un problema de naturaleza textual, cada palabra de una frase representando su relación con el resto de las palabras de la frase, por lo que en ese sentido se guarda una representación matemática que incluye contexto de cada palabra en la frase. Además, dada su estructura se logra conocer también la posición relativa de cada una de las palabras en el texto. En la Figura 8 se muestra la arquitectura de este tipo de red, para más información, consultar el paper original.

Esta misma idea se puede aplicar a la creación de música, generando un modelo que tome como entrada una secuencia de notas y genere otra secuencia. De esta forma, procesando el archivo de música MIDI en una secuencia de notas musicales (tokens), se pueden generar las nuevas secuencias gracias al cálculo de las capas de atención.
PoC
Para mostrar un ejemplo sobre la generación de música hemos llevado a cabo una demostración que utiliza una arquitectura GAN, adaptando el contenido ofrecido por AWS Deepcomposer. El objetivo perseguido es entrenar un modelo con música del famoso compositor clásico Johann Sebastian Bach, con el objetivo final de utilizar este modelo para utilizarlo por ejemplo con una melodía ya existente y hacer que suene más inspirada en Bach (concretamente, lo que hace es añadir tres nuevas pistas de piano a la recibida como input).
Transformers
Los Transformers son un tipo de red neuronal muy famosas en el ámbito del procesamiento del lenguaje natural, que han dado lugar a la generación de enormes modelos generadores de lenguaje, entre otras cosas, como GPT-3, desarrollado por OpenAI. Dadas una serie de palabras de entrada son capaces de generar párrafos enteros con una gran coherencia, y este tipo de modelos se caracterizan por tener una gran memoria, algo que por ejemplo constituía una limitación en las redes neuronales recurrentes.
Figura 13: Transformers
A grandes rasgos, este tipo de modelos trabajan con las denominadas capas de atención, las cuales codifican, por ejemplo, si se trata de un problema de naturaleza textual, cada palabra de una frase representando su relación con el resto de las palabras de la frase, por lo que en ese sentido se guarda una representación matemática que incluye contexto de cada palabra en la frase. Además, dada su estructura se logra conocer también la posición relativa de cada una de las palabras en el texto. En la Figura 8 se muestra la arquitectura de este tipo de red, para más información, consultar el paper original.

Figura 14: Arquitectura Transformers
Esta misma idea se puede aplicar a la creación de música, generando un modelo que tome como entrada una secuencia de notas y genere otra secuencia. De esta forma, procesando el archivo de música MIDI en una secuencia de notas musicales (tokens), se pueden generar las nuevas secuencias gracias al cálculo de las capas de atención.
PoC
Para mostrar un ejemplo sobre la generación de música hemos llevado a cabo una demostración que utiliza una arquitectura GAN, adaptando el contenido ofrecido por AWS Deepcomposer. El objetivo perseguido es entrenar un modelo con música del famoso compositor clásico Johann Sebastian Bach, con el objetivo final de utilizar este modelo para utilizarlo por ejemplo con una melodía ya existente y hacer que suene más inspirada en Bach (concretamente, lo que hace es añadir tres nuevas pistas de piano a la recibida como input).
En este caso, para esta demostración nos centraremos en la parte del aprendizaje del modelo, que se realiza gracias al entrenamiento de una red generativa antagónica. Siguiendo el funcionamiento de una GAN, el modelo generador trata de crear melodías inspiradas en Bach mientras que el modelo discriminador intenta discernir si las melodías que recibe como entrada suenan a este compositor o no, de manera que en cada iteración del entrenamiento cada modelo se vuelve mejor en su tarea.

Como se ha comentado, los datos consisten en melodías de Bach (JSB-Chorales-Dataset). El tamaño del dataset consta de 229 muestras, conteniendo cada una cuatro piano rolls correspondientes a las cuatro pistas que conforman cada melodía del dataset, donde cada piano roll tiene dimensiones de 32 pasos de tiempo * 128 tonos definidos en MIDI.
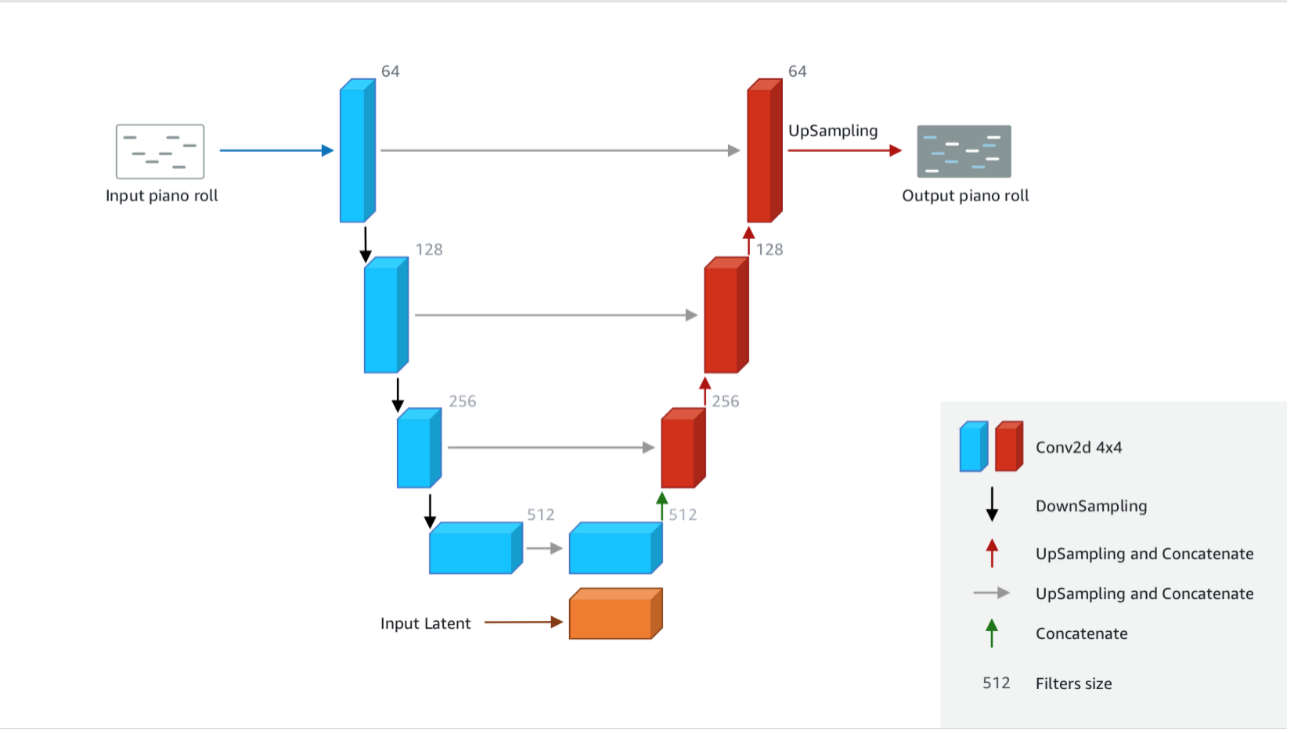
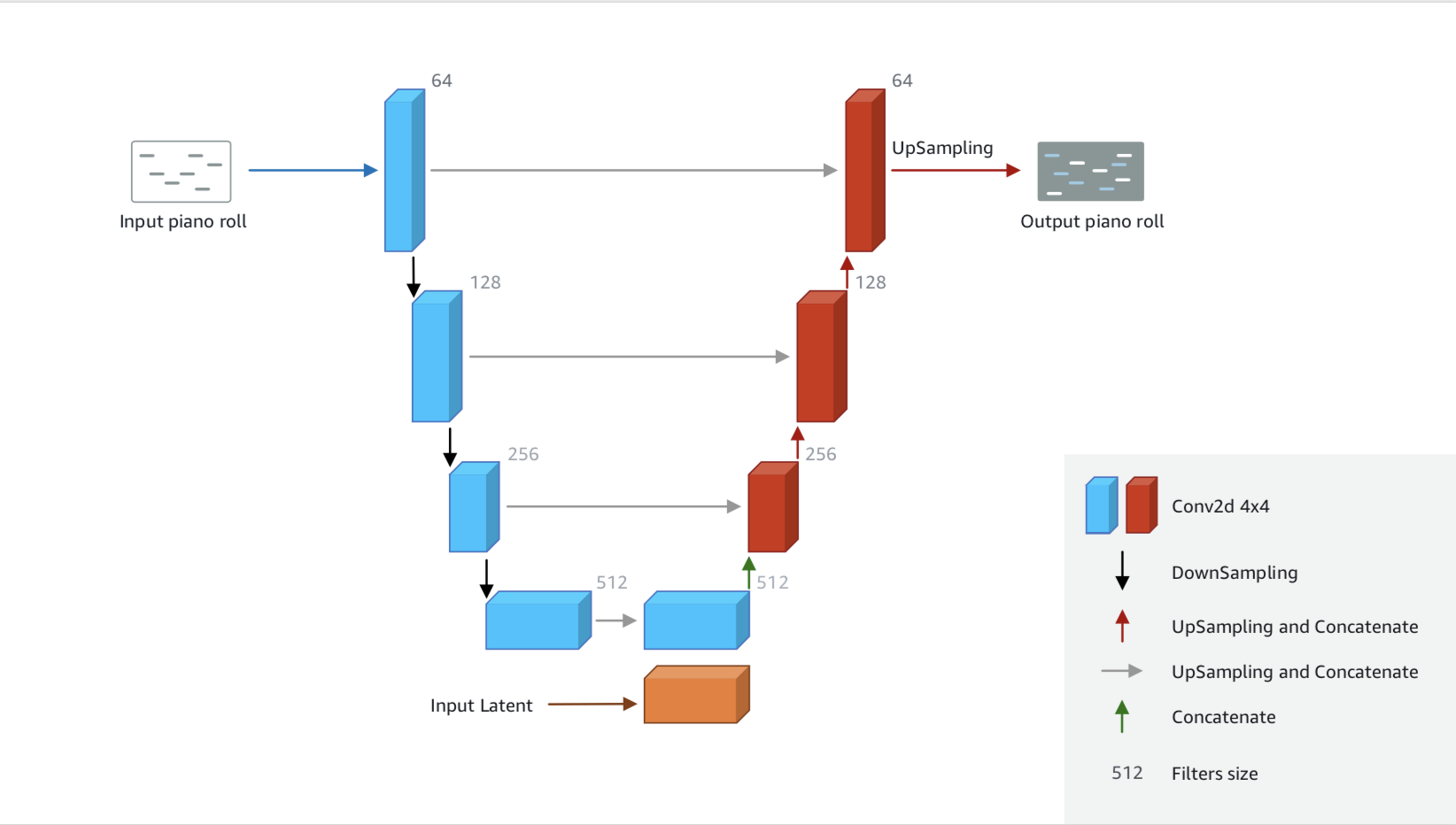
Figura 16: Arquitectura modelo Generador
El modelo generador es una red de neuronas artificial que recibe como entradas melodías del dataset (se escoge una sola pista de las cuatro), y genera melodías de cuatro pistas mediante la inserción de acompañamientos a las melodías recibidas como entrada. Además, también recibe como entrada una serie de números, conocidos como “vector de ruido”, cuyo objetivo es crear diferentes toques en las melodías a generar, para garantizar cierta variabilidad. Luego, utiliza el “veredicto” ofrecido por la red Discriminadora para ajustar sus pesos e intentar en la próxima iteración ajustarse más a la música de Bach.
La implementación de este modelo se muestra en el siguiente snippet de código, implementado en Keras (integrada en TensorFlow):
def _conv2d(layer_input, filters, f_size=4, bn=True):
"""Generator Basic Downsampling Block"""
d = tf.keras.layers.Conv2D(filters, kernel_size=f_size, strides=2,
padding='same')(layer_input)
d = tf.keras.layers.LeakyReLU(alpha=0.2)(d)
if bn:
d = tf.keras.layers.BatchNormalization(momentum=0.8)(d)
return d
def _deconv2d(layer_input, pre_input, filters, f_size=4, dropout_rate=0):
"""Generator Basic Upsampling Block"""
u = tf.keras.layers.UpSampling2D(size=2)(layer_input)
u = tf.keras.layers.Conv2D(filters, kernel_size=f_size, strides=1,
padding='same')(u)
u = tf.keras.layers.BatchNormalization(momentum=0.8)(u)
u = tf.keras.layers.ReLU()(u)
if dropout_rate:
u = tf.keras.layers.Dropout(dropout_rate)(u)
u = tf.keras.layers.Concatenate()([u, pre_input])
return u
def build_generator(condition_input_shape=(32, 128, 1), filters=64,
instruments=4, latent_shape=(2, 8, 512)):
"""Buld Generator"""
c_input = tf.keras.layers.Input(shape=condition_input_shape)
z_input = tf.keras.layers.Input(shape=latent_shape)
d1 = _conv2d(c_input, filters, bn=False)
d2 = _conv2d(d1, filters * 2)
d3 = _conv2d(d2, filters * 4)
d4 = _conv2d(d3, filters * 8)
d4 = tf.keras.layers.Concatenate(axis=-1)([d4, z_input])
u4 = _deconv2d(d4, d3, filters * 4)
u5 = _deconv2d(u4, d2, filters * 2)
u6 = _deconv2d(u5, d1, filters)
u7 = tf.keras.layers.UpSampling2D(size=2)(u6)
output = tf.keras.layers.Conv2D(instruments, kernel_size=4, strides=1,
padding='same', activation='tanh')(u7) # (32, 128, 4)
generator = tf.keras.models.Model([c_input, z_input], output, name='Generator')
return generator(Acaba en la tercera parte de este artículo, comenzando con la arquitectura y el código del modelo Discriminador.)
- ¿Utilizar Inteligencia Artificial para convertirnos en mejores músicos? Parte 2
- ¿Utilizar Inteligencia Artificial para convertirnos en mejores músicos? Parte 3
**************************************************************************************************
Saludos,
Autor: Javier del Pino Díaz (Intership en Ideas Locas)

Via: www.elladodelmal.com
¿Utilizar Inteligencia Artificial Para Convertirnos En Mejores Músicos? Parte 2 De 3
 Reviewed by Zion3R
on
0:11
Rating:
Reviewed by Zion3R
on
0:11
Rating:
Reviewed by Zion3R
on
0:11
Rating:




{kind=link}
{kind=link}