Xcrawl3R - A CLI Utility To Recursively Crawl Webpages

xcrawl3r is a command-line interface (CLI) utility to recursively crawl webpages i.e systematically browse webpages' URLs and follow links to discover linked webpages' URLs.
Features
- Recursively crawls webpages for URLs.
- Parses URLs from files (
.js,.json,.xml,.csv,.txt&.map). - Parses URLs from
robots.txt. - Parses URLs from sitemaps.
- Renders pages (including Single Page Applications such as Angular and React).
- Cross-Platform (Windows, Linux & macOS)
Installation
Install release binaries (Without Go Installed)
Visit the releases page and find the appropriate archive for your operating system and architecture. Download the archive from your browser or copy its URL and retrieve it with wget or curl:
-
...with
wget:wget https://github.com/hueristiq/xcrawl3r/releases/download/v<version>/xcrawl3r-<version>-linux-amd64.tar.gz -
...or, with
curl:curl -OL https://github.com/hueristiq/xcrawl3r/releases/download/v<version>/xcrawl3r-<version>-linux-amd64.tar.gz
...then, extract the binary:
tar xf xcrawl3r-<version>-linux-amd64.tar.gzTIP: The above steps, download and extract, can be combined into a single step with this onliner
curl -sL https://github.com/hueristiq/xcrawl3r/releases/download/v<version>/xcrawl3r-<version>-linux-amd64.tar.gz | tar -xzv
NOTE: On Windows systems, you should be able to double-click the zip archive to extract the xcrawl3r executable.
...move the xcrawl3r binary to somewhere in your PATH. For example, on GNU/Linux and OS X systems:
sudo mv xcrawl3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add xcrawl3r to their PATH.
Install source (With Go Installed)
Before you install from source, you need to make sure that Go is installed on your system. You can install Go by following the official instructions for your operating system. For this, we will assume that Go is already installed.
go install ...
go install -v github.com/hueristiq/xcrawl3r/cmd/xcrawl3r@latestgo build ... the development Version
-
Clone the repository
git clone https://github.com/hueristiq/xcrawl3r.git -
Build the utility
cd xcrawl3r/cmd/xcrawl3r && \ go build . -
Move the
xcrawl3rbinary to somewhere in yourPATH. For example, on GNU/Linux and OS X systems:sudo mv xcrawl3r /usr/local/bin/NOTE: Windows users can follow How to: Add Tool Locations to the PATH Environment Variable in order to add
xcrawl3rto theirPATH.
NOTE: While the development version is a good way to take a peek at xcrawl3r's latest features before they get released, be aware that it may have bugs. Officially released versions will generally be more stable.
Usage
To display help message for xcrawl3r use the -h flag:
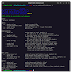
xcrawl3r -hhelp message:
_ _____ __ _____ _ __ __ ___ _| |___ / _ __ \ \/ / __| '__/ _` \ \ /\ / / | |_ \| '__| > < (__| | | (_| |\ V V /| |___) | | /_/\_\___|_| \__,_| \_/\_/ |_|____/|_| v0.1.0A CLI utility to recursively crawl webpages.USAGE: xcrawl3r [OPTIONS]INPUT: -d, --domain string domain to match URLs --include-subdomains bool match subdomains' URLs -s, --seeds string seed URLs file (use `-` to get from stdin) -u, --url string URL to crawlCONFIGURATION: --depth int maximum depth to crawl (default 3) TIP: set it to `0` for infinite recursion --headless bool If true the browser will be displayed while crawling. -H, --headers string[] custom header to include in requests e.g. -H 'Referer: http://example.com/' TIP: use multiple flag to set multiple headers --proxy string[] Proxy URL (e.g: http://127.0.0.1:8080) TIP: use multiple flag to set multiple proxies --render bool utilize a headless chrome instance to render pages --timeout int time to wait for request in seconds (default: 10) --user-agent string User Agent to use (default: web) TIP: use `web` for a random web user-agent, `mobile` for a random mobile user-agent, or you can set your specific user-agent.RATE LIMIT: -c, --concurrency int number of concurrent fetchers to use (default 10) --delay int delay between each request in seconds --max-random-delay int maximux extra randomized delay added to `--dalay` (default: 1s) -p, --parallelism int number of concurrent URLs to process (default: 10)OUTPUT: --debug bool enable debug mode (default: false) -m, --monochrome bool coloring: no colored output mode -o, --output string output file to write found URLs -v, --verbosity string debug, info, warning, error, fatal or silent (default: debug)Contributing
Issues and Pull Requests are welcome! Check out the contribution guidelines.
Licensing
This utility is distributed under the MIT license.
Credits
-
Alternatives - Check out projects below, that may fit in your workflow:
Via: www.kitploit.com
 Reviewed by Zion3R
on
19:43
Rating:
Reviewed by Zion3R
on
19:43
Rating: